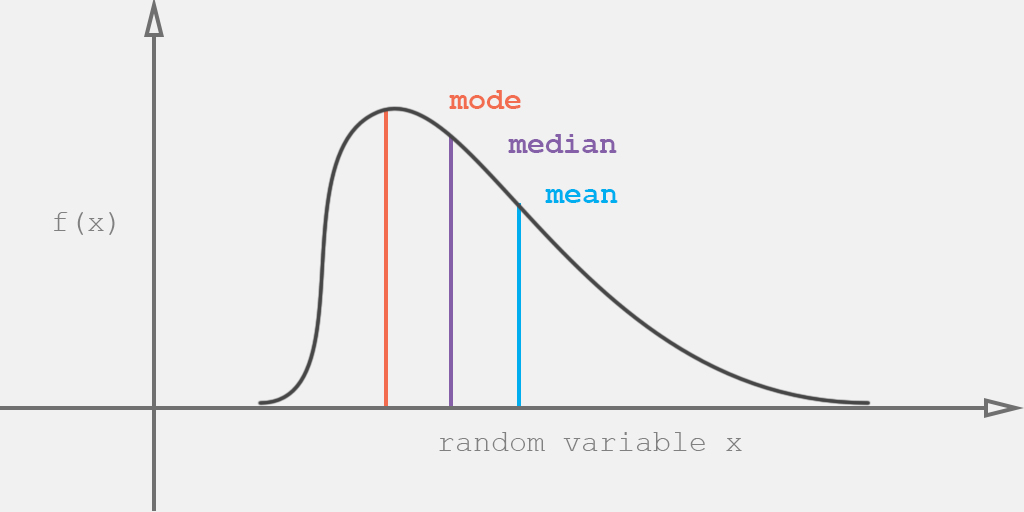
Measures of location are a means of acquiring and describing the central tendency of a certain amount of data or distribution. The most common are mean, median and mode, despite these may be called as "average" (more formally, a measure of central tendency).