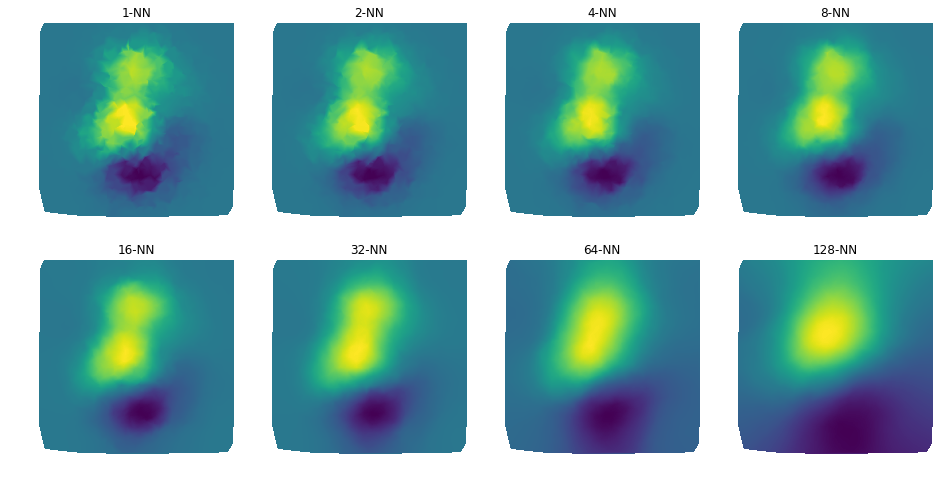
k-Nearest Neighbors

The k-nearest neighbors algorithm (or k-NN) is an instance-based learning method that can be used for either classification or prediction, depending on the input data.
The main goal of this post is to make a quick description and implementation of the algorithm( from scratch), as clear and intuitive as possible. All the following models will be developed using only Python and NumPy and no real dataset will be used (only data biasedly produced) for a better understanding and visualization of the results.
You can access all the examples and codes in this post by visiting these two notebooks: k-NN Classification and k-NN Regression.
Introduction to k-NN
As you can notice after reading the name of the algorithm, it is mainly supposed to classify or predict based on neighbor data samples. Thus, the parameter k defines the number of nearest neighbors that will be considered for both situation. If k is equal to 1 ($k=1$) then the object to be inferred will be labeled (or predicted) with the same class (or value) of its closest neighbor, given a vectorial space. If $k=n$ so the inference consider its n-closest neighbors, as you can see in the following image:
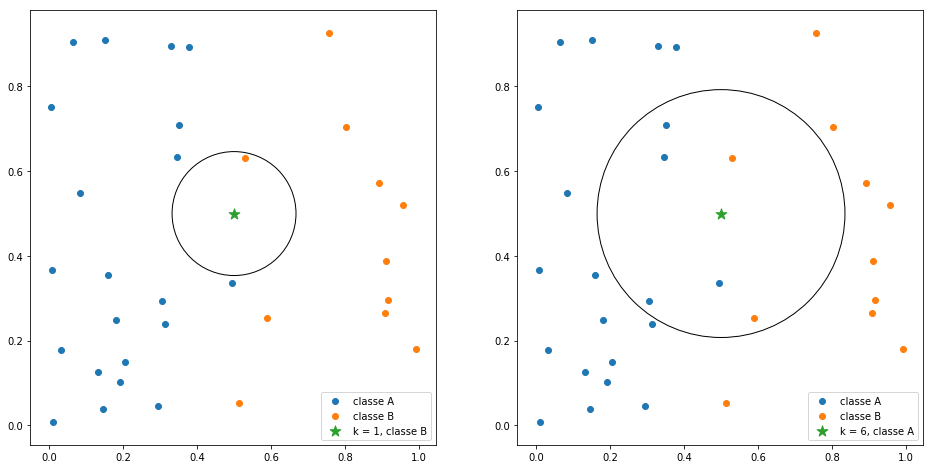
You might be thinking: "How do I know which data points are the closest to my object?".. The answer is dissimilarity and distance measure, given the $\mathbb{R}^n$ space. There is a number of methods to measure distances but for the following examples lets consider only the Euclidean Distance, defined as:
Given that, let's start by creating a distance class so we can use in our classification and prediction algorithms.
class Distance(object):
def __init__(self):
super().__init__()
def euclidean(self, p, q):
return np.sum((p - q)**2, axis=1)**0.5Classification using k-NN
The result of the classification process of a k-NN model is the prediction of a categorical variable. The target object will be labeled based on the ranking of classes from its closest neighbors so the most frequent label will be chosen.
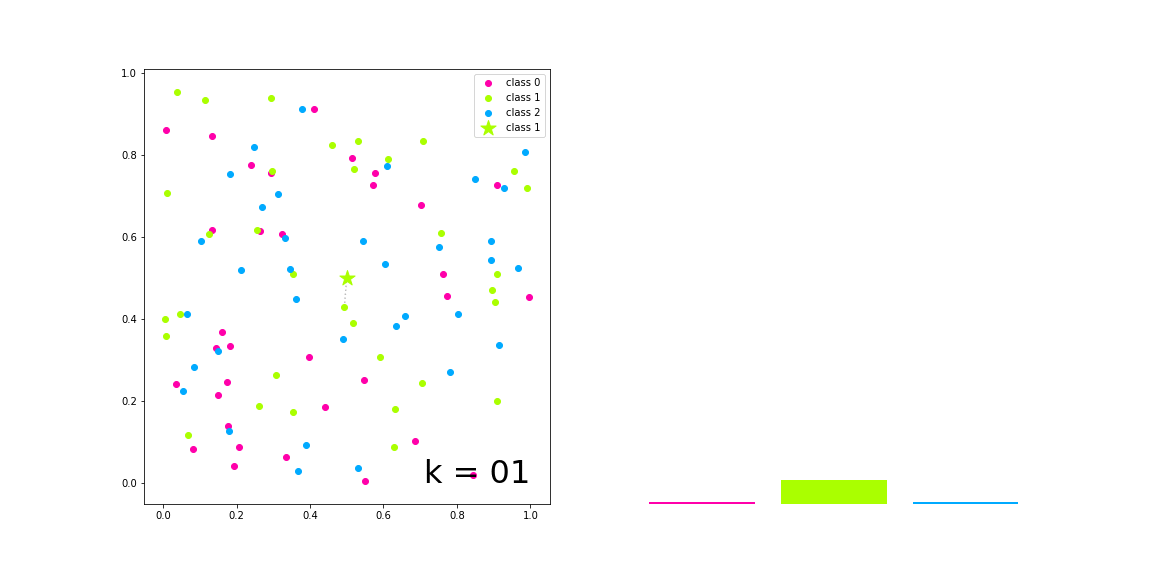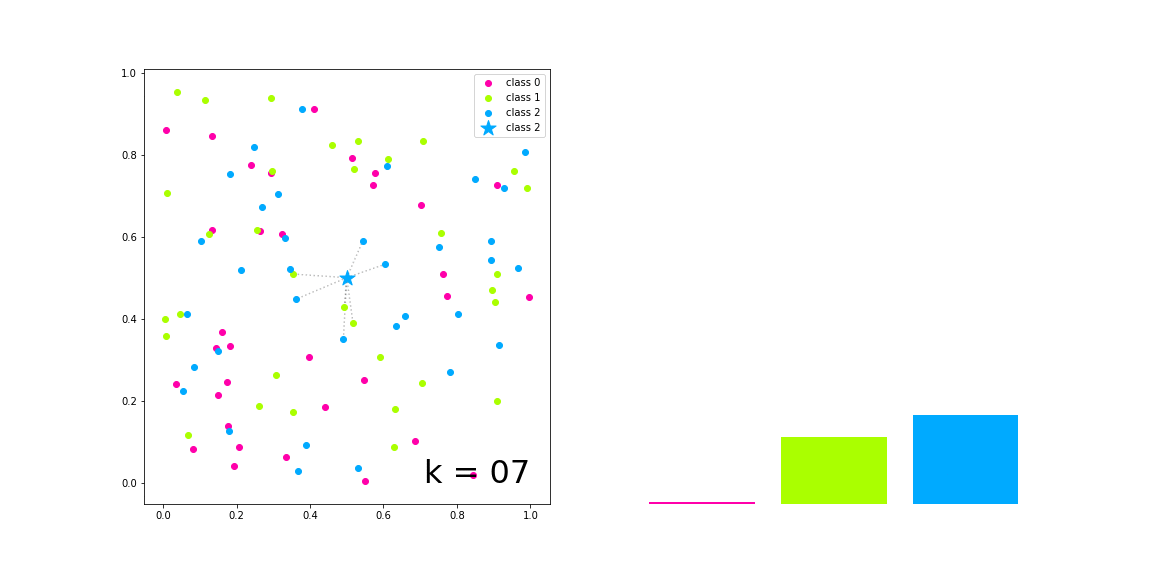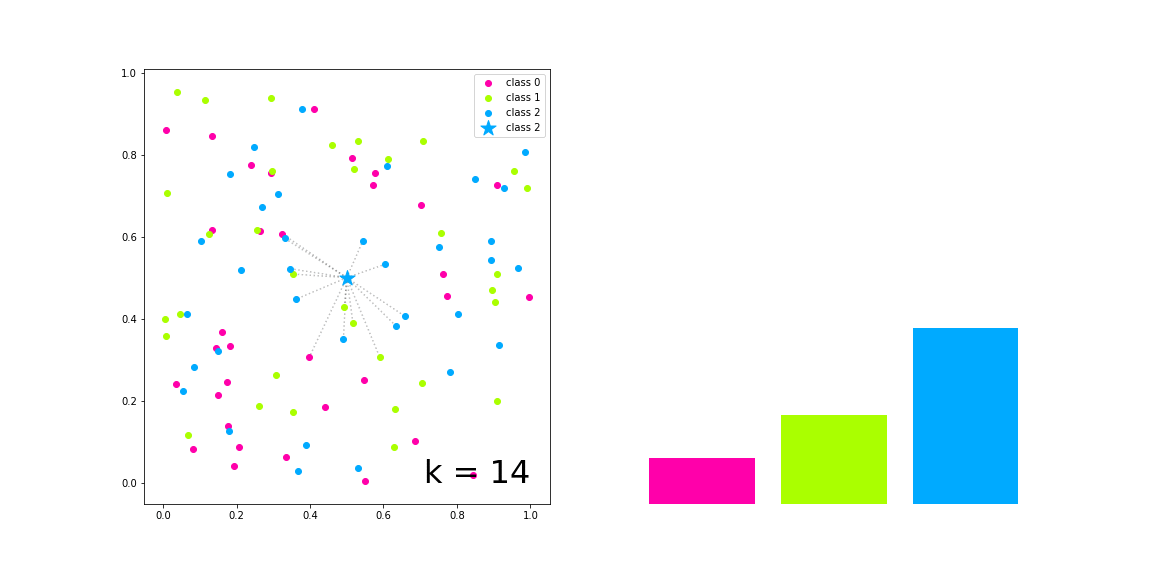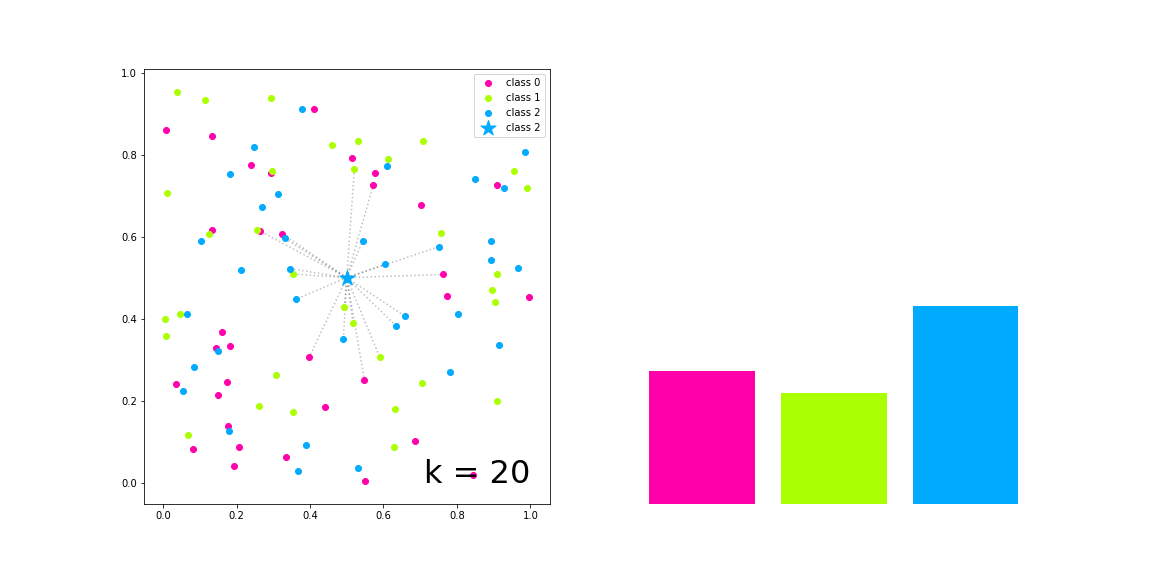
The implementation of this algorithm is done as a class that inherits the Distance class, previously implemented.
class kNNClass(Distance):
def __init__(self, k=1):
super().__init__()
self._k = k
self._q = None
self._class = None
def fit(self, X, y):
self._q = X
self._class = y
def pred(self, P):
y, NNs = [], []
for i, p in enumerate(P):
dist = self.euclidean(p, self._q)
odist = np.argsort(dist)[:self._k]
fdist = np.ravel(self._class[odist])
hist = np.bincount(fdist)
index = np.argmax(hist)
y += [index]
NNs += [odist]
return np.array(y), np.array(NNs)The method fit trains the model by associating each sample point X to its respective class y. Therefore, the method pred predicts the predicting class to each object p considering the most frequent class from its k-neighbors.
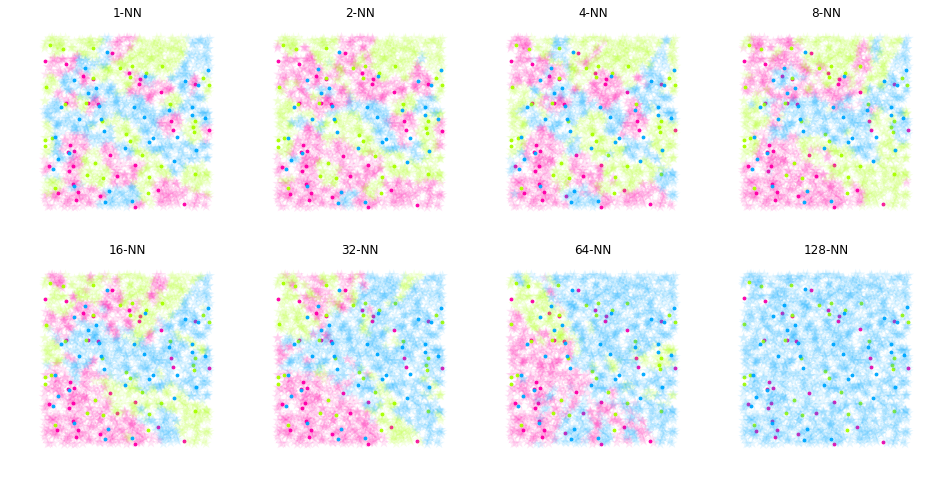
Prediction using k-NN
Similarly to the classification algorithm, the prediction process of a k-NN model aims to define a result based on neighborhood but, in this case, we want to find non-categorical values. This process is realized by something similar to a regression analysis, which the output is a mean value weighted by the proportional inverse of the distance from each neighbor. For example, given a ground truth function Z (left), we can extract some sample to be used as training data points (right).
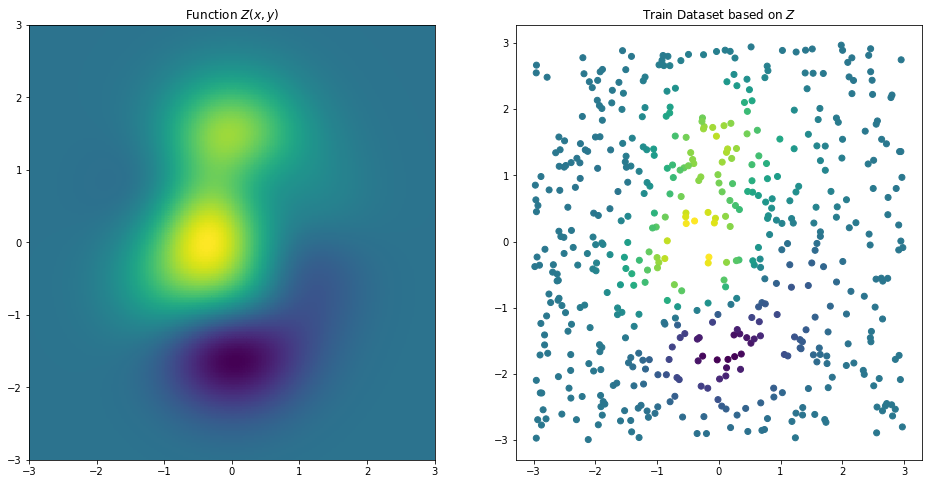
On the same way of the classification, the implementation of this algorithm is done as a class which inherits the Distance class.
class kNNRegr(Distance):
def __init__(self, k=1):
super(kNNRegr, self).__init__()
self._k = k
self._q = None
self._v = None
def fit(self, X, y):
self._q = X
self._v = y
def pred(self, P):
y, NNs = [], []
for i, p in enumerate(P):
dist = self.euclidean(p, self._q)
odist = np.argsort(dist)[:self._k]
fdist = np.ravel(self._v[odist])
ndist = dist[odist]
ndist /= np.sum(ndist)
y += [np.sum(fdist*np.flipud(ndist))]
NNs += [odist]
return np.array(y), np.array(NNs)The method fit trains the model by associating each sample of training point X to its respective dependent variable value y. However, the method pred predicts the value by realizing a distance-weighted mean of the respective values v of its neighbors. The final result is an interpolated value which approaches to the function Z depending on the parameter k.